
Harnessing the power of cloud computing has become a cornerstone for modern digital solutions, and Google Cloud Functions stands out as a versatile tool for various applications. In particular, its potential for auto indexing is gaining traction among developers and businesses seeking efficiency and automation. This serverless execution environment allows code to run in response to external events, enabling seamless automation of indexing tasks. By eliminating the need for manual interventions and costly infrastructure management, Google Cloud Functions offers a scalable, cost-effective solution for dynamically updating indexes. This article explores how auto indexing with Google Cloud Functions can streamline workflows and enhance data management strategies.
Benefits of Using Google Cloud Functions for Auto Indexing
What Are Google Cloud Functions?
Google Cloud Functions are a serverless execution environment provided by Google Cloud where you can run your code in response to events. Functions scale automatically and you are charged only for the actual compute time used. These functions are built in various programming languages such as Python, JavaScript, and Go, making them versatile for different developer needs. The serverless nature means you don’t need to manage the underlying infrastructure yourself, which speeds up application development and reduces maintenance overhead.
How Auto Indexing Works with Google Cloud Functions
Auto indexing involves automatically updating and managing indexes in a database or a search platform to ensure optimal retrieval speed and accuracy. With Google Cloud Functions, triggers can be created to automatically index new data entries as they are added or updated in a database. This ensures that the database is always kept up-to-date without manual intervention. By integrating with other Google Cloud services like Pub/Sub or Firestore, these triggers can listen to changes and initiate indexing tasks instantly. The flexibility of functions allows you to implement custom indexing logic tailored to your specific data and query requirements.
Advantages of Serverless Auto Indexing
Serverless architectures like Google Cloud Functions provide several advantages for auto indexing. First, they offer scalability, enabling functions to handle varying loads without pre-provisioning server capacity. Second, they offer cost-efficiency, as you are charged only for the computation that directly correlates with the resource usage. Third, by being built on event-driven architectures, these functions can respond instantaneously to changes in data, ensuring that indexes are updated in real-time. Lastly, they reduce complexity and operational overhead since serverless functions abstract away much of the infrastructure and scaling concerns from the developer.
Integrating Google Cloud Functions with Other Cloud Services
One of the most powerful aspects of Google Cloud Functions is their ability to easily integrate with other services within the Google Cloud ecosystem. For instance, Google Cloud Storage can be used to store large amounts of data and Cloud Functions can trigger indexing whenever new files are uploaded. You can also use Google Pub/Sub to send messages about data changes, triggering the functions instantly for indexing tasks. Additionally, Firestore and BigQuery can be directly connected to Cloud Functions for seamless data flow and processing, enhancing the overall data handling and indexing capability of your applications.
Potential Challenges and Solutions in Implementing Auto Indexing
While there are numerous benefits to using Google Cloud Functions for auto indexing, some challenges may arise. One potential challenge is managing complex indexing logic, which can be mitigated by breaking it down into smaller, modular functions. Latency is another concern, especially for large datasets, which can be addressed through efficient function design and optimization techniques like caching. Monitoring and debugging can also become complex in a distributed serverless environment, but Google Cloud offers integrated tools like Stackdriver for effective logging and performance monitoring, ensuring that any issues can be quickly identified and resolved.
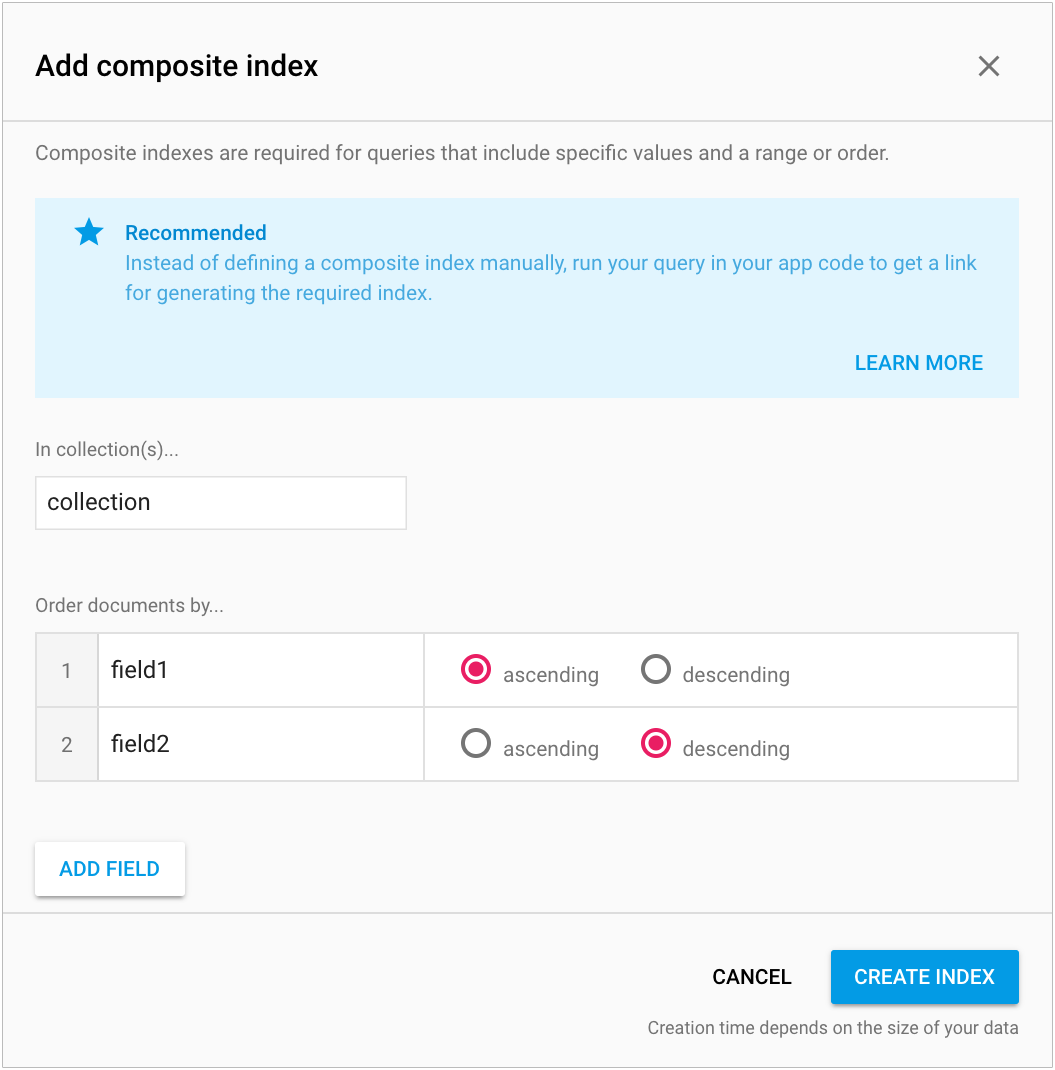
| Feature | Description |
|---|---|
| Serverless | Allows for automatic scaling and infrastructure management, reducing developer overhead. |
| Event-Driven | Functions are triggered by specific events, facilitating real-time indexing updates. |
| Cost-Efficiency | Billing is based on exact compute resources used, optimizing budget usage. |
| Integration | Works seamlessly with other Google Cloud services for enhanced functionality. |
| Scalability | Functions automatically adjust to varying demand levels without manual intervention. |
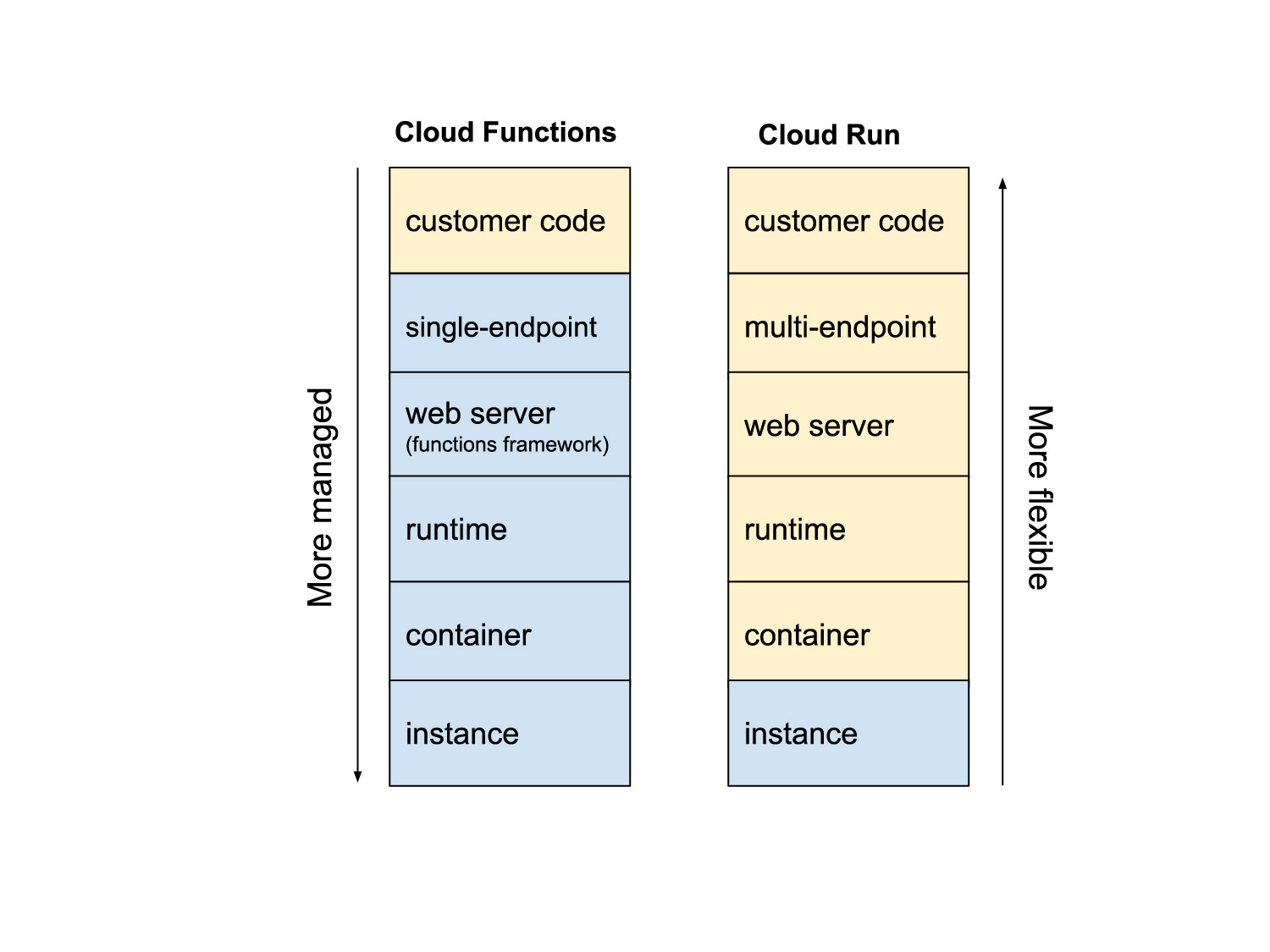
What are the limitations of cloud run Functions?
Scalability and Performance Concerns
Cloud Run Functions offer a serverless platform that automatically scales with incoming requests. However, there are certain limitations related to scalability and performance:
- Cold Start Delays: Instances may take a few seconds to start when there’s no existing traffic, leading to initial response delays.
- Throughput Limits: Though automatically scale, there are maximum limits on concurrent requests and instance usage.
- Resource Constraints: Cloud Run Functions have limitations in terms of memory and CPU, which can affect the performance of computationally intensive tasks.
Deployment and Runtime Limitations
Deploying applications on Cloud Run Functions comes with certain considerations that might not suit every use case:
- Language Support: While multiple programming languages are supported, the offered runtime environments may not cover all desired versions or setups.
- Timeouts: There is a maximum request duration limit, typically around 15 minutes, which can hinder long-running processes.
- Ephemeral Storage: Cloud Run Functions rely on temporary storage, which can affect tasks requiring persistent state across requests.
Cost Implications and Billing Challenges
While Cloud Run Functions offer a pay-per-use model that is typically cost-effective, certain factors can lead to unexpected costs:
- Rapid Scaling Costs: High traffic may rapidly increase the number of instances running, inadvertently increasing costs.
- Billing Complexity: Cost calculation can become complex due to various factors like request count, CPU, memory, and network usage.
- Under-utilization: For applications with consistent loads, the serverless model may not always provide the most cost-efficient solution compared to reserved instances.
What types of indexes are automatically created in cloud Firestore?
Single-Field Indexes
Cloud Firestore automatically creates single-field indexes for each field in a document. These indexes allow for efficient queries on individual fields. Here is a more detailed list:
- Each field in a document is indexed separately.
- Single-field indexes support simple queries, such as equalities or basic sorting.
- They enable straightforward usage of filters and ordering for specific fields in queries.
Automatic Index Creation for Queries
Automatically created indexes in Cloud Firestore are designed to support queries without the need for any manual setup. Here are some key points:
- Indexes are automatically created for queries that only involve single fields, which are needed for queries involving sorting or filtering.
- Firestore optimizes index creation based on your database traffic and usage patterns.
- The automatic indexing process helps ensure optimal performance without explicit configuration needs by the developer.
Limitations and Exceptions in Automatic Indexing
While automatic indexing is convenient, there are limitations and exceptions. Here is what to consider:
- Not all queries can be served through automatic indexes, particularly those involving multiple fields with complex conditions.
- There is a limit to the number of automatic indexes due to storage and performance considerations, potentially necessitating manual index creation for complex queries.
- Indexes for fields that contain large arrays or map values are not automatically created, as these structures can become complex and resource-intensive.
What is the primary purpose of Google Cloud Functions?
Google Cloud Functions primarily serve as a serverless compute service that allows developers to run code in response to events without having to worry about managing or provisioning servers. It’s designed to streamline the development process and offer a more efficient way to build scalable and flexible applications in the cloud.
How Does Google Cloud Functions Enable Event-Driven Architecture?
Google Cloud Functions is integral to facilitating an event-driven architecture by automatically executing code in response to specific events.
– Automation: Functions can be triggered automatically in response to changes in data, such as updates to a database or modifications to a storage bucket.
– Integration with Other Services: It seamlessly interfaces with other Google Cloud services, such as Pub/Sub and Firebase, ensuring dynamic responses to a variety of cloud events.
– Scalability: It automatically scales with demand, handling from a few events per day to millions, without needing intervention by the developer.
What are the Benefits of Using Google Cloud Functions for Developers?
Developers benefit significantly from using Google Cloud Functions due to its simplification of deployment and maintenance procedures.
– No Infrastructure Management: There is no need to manage or configure infrastructure, allowing developers to focus solely on writing and deploying code.
– Cost-Efficiency: Charges are incurred only for the function’s execution time, which can lead to cost savings, particularly for infrequent or unpredictable workloads.
– Rapid Development: Developers can quickly iterate and deploy new updates to functions, speeding up the process of innovation and adaptation to user needs.
How Does Google Cloud Functions Assist in Building Microservices?
Google Cloud Functions facilitates the creation of microservices by allowing developers to deploy small, independent, and loosely coupled pieces of code.
– Functional Isolation: Each function can be developed, deployed, and scaled independently, which aligns with the principles of microservice architecture.
– Enhanced Modularity: Functions promote a modular codebase where individual functions can communicate through APIs, allowing for better code organization.
– Language Support: It supports multiple programming languages including JavaScript, Python, and Go, offering flexibility to use the best tool for each specific task.
What is the difference between Google Cloud Run and Google Cloud Functions?
Deployment Model
Google Cloud Run and Google Cloud Functions differ significantly in terms of their deployment models:
- Google Cloud Run: This service allows users to deploy containerized applications. You package your application and its dependencies into a container, giving you greater flexibility in terms of languages, libraries, and tools you can use.
- Google Cloud Functions: Here you can deploy individual functions. It’s designed for deploying small units of code that respond to events without worrying about the underlying infrastructure. You write and deploy functions without the need to package the entire application environment.
Use Cases
Cloud Run and Cloud Functions cater to different use cases, each serving distinct application needs:
- Google Cloud Run: It is suitable for applications that need a fully managed environment for any code that can run in a container, making it ideal for web applications, APIs, and stateful services where controlling the entire application stack is necessary.
- Google Cloud Functions: This is perfect for event-driven workloads. It’s primarily used for tasks such as data processing, real-time file/events processing, and simple REST APIs, where you need scalability, but not full control over the runtime environment.
Scaling and Performance
In terms of scalability and performance, Cloud Run and Cloud Functions offer different features and capabilities:
- Google Cloud Run: Offers automatic scaling and can handle stateless containers, scaling from zero to many instances based on incoming traffic. It provides more control over the concurrency, which can be important for handling traffic spikes smoothly.
- Google Cloud Functions: Also scales automatically, but it is designed to run single-purpose functions. Cloud Functions scale based on the number of incoming events, and while it offers simplicity, you have less control over how it scales compared to Cloud Run.
Frequently Asked Questions
What are Google Cloud Functions and how can they be used for auto indexing?
Google Cloud Functions is a serverless execution environment for building and connecting cloud services. With Cloud Functions, you write simple, single-purpose functions that are attached to events emitted from your cloud infrastructure and services. Essentially, these functions allow you to execute your code in response to triggers, such as changes in a storage bucket or incoming HTTP requests. When it comes to auto indexing, Google Cloud Functions can automatically react to events and update the index of your data. For example, a change in a database can trigger a function to update a search index, ensuring that the indexed information remains up-to-date without manual intervention. This makes Cloud Functions ideal for creating responsive, scalable, and efficient auto indexing systems.
How does auto indexing with Google Cloud Functions improve efficiency in data management?
Auto indexing with Google Cloud Functions significantly improves efficiency by automating the process of updating indexes whenever changes occur in your dataset. Traditionally, manual indexing might lead to delays or human error, as it requires continuous monitoring and manual execution of indexing tasks. Google Cloud Functions eradicates these issues by instantly triggering and executing indexing routines as soon as data changes are detected. This automation ensures that all entries in the index are current and accurately reflect the latest data, thereby enhancing the overall reliability and performance of your application. Furthermore, the serverless nature of Cloud Functions means that you are only charged for the execution time of your functions, reducing operational costs compared to maintaining a server infrastructure.
What are the best practices for integrating Google Cloud Functions into an auto indexing workflow?
To successfully integrate Google Cloud Functions into an auto indexing workflow, it’s important to follow a set of best practices. First, design your functions to be as stateless as possible. Stateless functions are more scalable and easier to manage, allowing them to rapidly handle numerous indexing events. Second, leverage triggers effectively by connecting functions to the most relevant events such as updates in a database or file changes within a cloud storage system. Third, ensure robust error handling and logging to troubleshoot issues quickly whenever a function doesn’t execute as expected. This can be achieved by using Cloud Logging and Monitoring tools to track performance metrics and error rates. Finally, optimize the execution time of each function to keep costs low and performance high, focusing on writing efficient and lightweight code.
What are potential challenges when using Google Cloud Functions for auto indexing, and how can they be overcome?
One potential challenge of using Google Cloud Functions for auto indexing is handling the concurrency of multiple events triggering functions simultaneously. If not managed properly, this can lead to race conditions or low performance. This can be overcome by implementing idempotency in your functions, ensuring that repeated executions result in the same state as a single execution. Another challenge could be the function’s execution time limit, as Cloud Functions are designed to handle quick processes. For complex indexing operations that exceed this time limit, you might need to break down the tasks into smaller chunks or use Cloud Tasks to queue and schedule execution. Additionally, handling large data sets can be challenging due to memory constraints; solutions involve optimizing data processing logic or utilizing other Google Cloud services, such as BigQuery, to manage data more efficiently. By anticipating these challenges and planning accordingly, you can create a robust auto indexing system with Google Cloud Functions.